Notebook
Here's where we post periodic updates on what we've been up to at Fathom. Reflections on the interesting stories that emerge from our client work, side projects, after-hours rabbitholes, and other miscellaneous threads of inquiry.
You can also follow these posts as a feed in your feed reader.

Last week, I spoke on a panel about careers in information design and visualization hosted by Data Visualization Society for Northeastern University's Information Design and Data Visualization (IDDV) master’s program. We each had 10–12 minutes to say our piece, so in the interest of sharing something coherent within the allotted time, I wrote down my thoughts in advance, which you can find below. With ten minutes, it’s not a comprehensive guide to finding a career, but I wanted to at least pose a few questions that might help the students focus their search.


Katherine reflects on how we've been thinking and talking about generative AI in the studio.

2025 was a pretty mind-blowing year for our work in pandemic preparedness.

Sentinel, our long-time collaboration with the Sabeti Lab and IGH, has been awarded the MacArthur Foundation 100&Change grant.

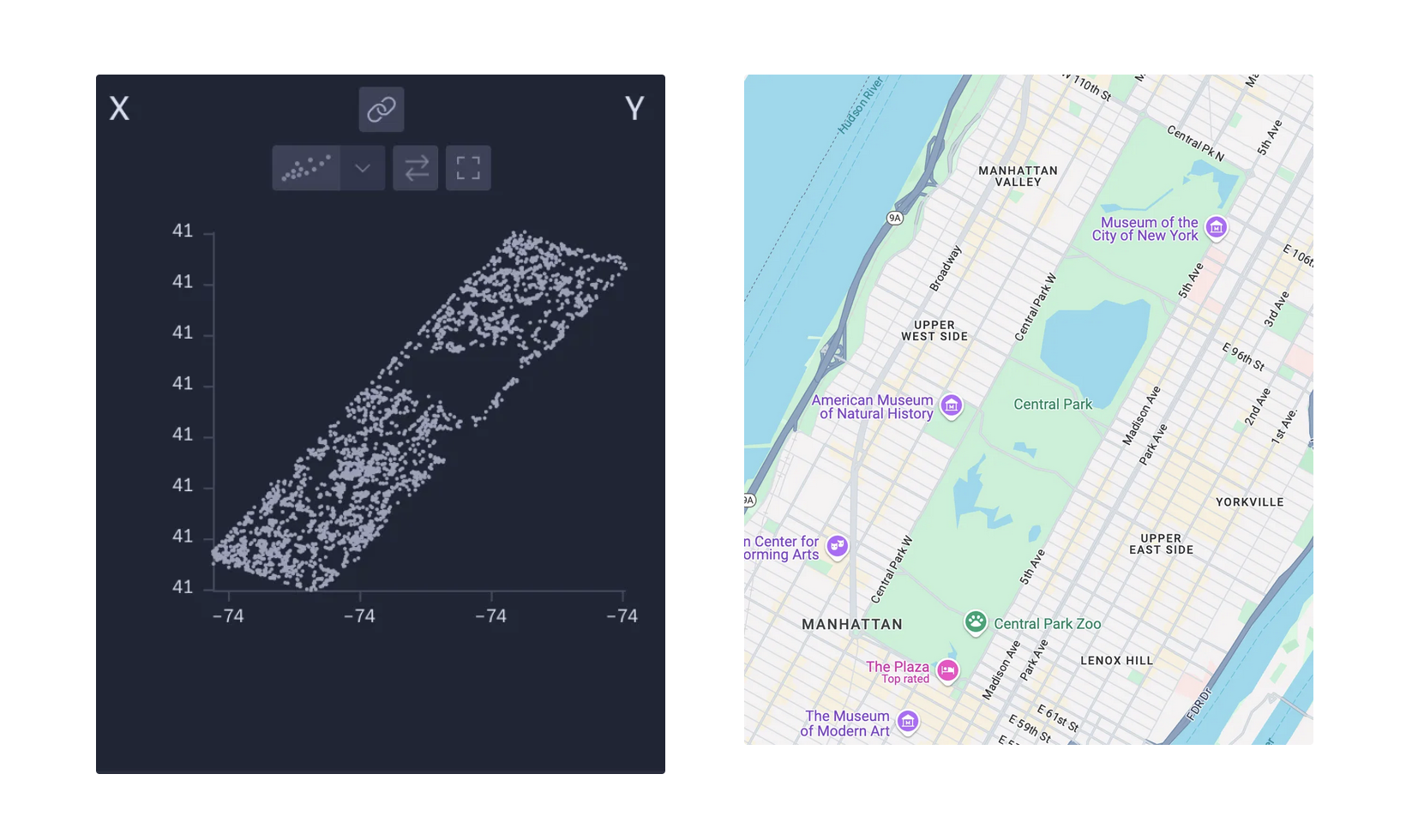
Faster exploration with larger files, right on your desktop.

New features on our one-year anniversary of launching Rowboat!

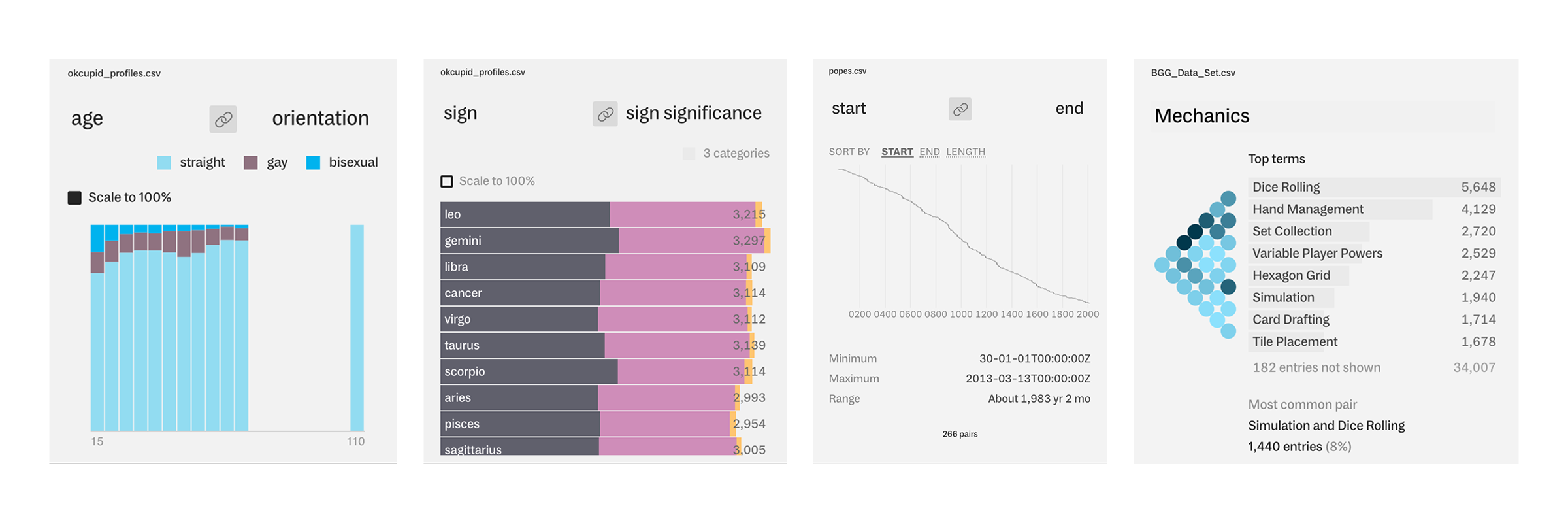
Lots to share since launching Rowboat: stacks, ranges, bars, and more to come!