


I spent this summer working as an intern at Fathom. From the experience, I’ve learned a substantial amount about computer science and information design. Working with old FBI documents taught me about text recognition and natural language processing. While working with videos from Osama Bin Laden’s compound, I learned about face recognition software and the use of machine learning to analyze image data. My investigation of Wikipedia data pushed me to understand the complications that often arise with especially large sets of data, and to consider efficiency of memory allocation in programs. In every project, I expanded my programming understanding and ability, and I’m incredibly appreciative of the opportunity to do so in such a motivating and inspiring environment.
Videos from the Abbottabad Archive
My first few weeks at Fathom were focused on finding a way to bring structure to large amounts of unlabeled video data from the Abbottabad files. Released in 2017 by the CIA, the document set consists of almost 470,000 video, audio, and text files collected from the computers in Osama Bin Laden’s compound in Abbottabad, Pakistan. Since the videos lacked meaningful file names, helpful metadata, or any folder structure, we needed other ways to organize and provide hierarchy to the 8,000 hours of video footage.

For a first attempt, I aimed to organize the videos by analyzing faces and grouping the videos based on the people who appear in each. The algorithm I used calculates an embedding — a list of 128 facial measurements that can, fairly accurately, uniquely identify a face — and plots that list of 128 numbers in 128 dimensions. It then clusters all the data points based on proximity to one another. Points that are close together are determined to be the face of the same person, and the videos featuring that person are grouped together.
This program is very effective with certain types of images, such as a test set we used of celebrity photos from red carpet events (other than an occasional — and understandable — mix-up between Matt Damon and Brad Pitt). It remained fairly accurate even with high resolution clips from movies and TV shows. However, the embeddings become less reliable when people aren’t directly facing the camera, or when the resolution of the image is too grainy to accurately calculate measurements. Since the Abbottabad files are extremely low quality, this clustering method proved less effective than desired. Additionally, many videos don’t contain people or instead feature cartoon characters, which prompted us to look for another method of organization.


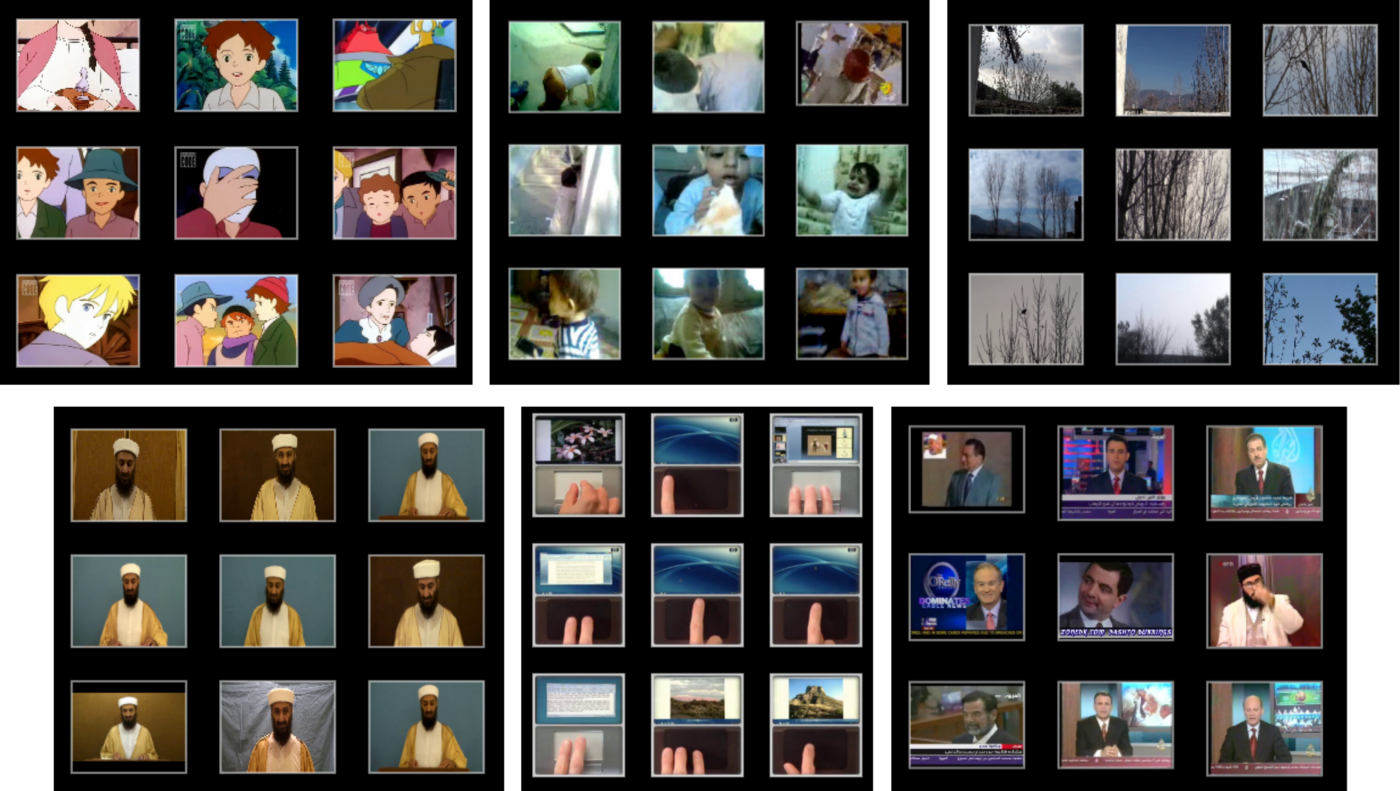
For a second approach, I looked at clustering the videos based on the entire frame rather than only looking at people. The program I used parses one frame from each video, and passes the image through a neural net trained on images from ImageNet (an open source database of tagged images). The neural net then calculates a fingerprint for each image, which represents a small amount of information that can uniquely identify the image.
Clustering the fingerprints produces remarkably accurate results, including groups of videos featuring cartoons, young children, outdoor scenes, Bin Laden, instructional videos for how to use a trackpad, and news reporters (and a mistaken video of Mr. Bean). If any one cluster contains more than 60% of the data, the program breaks this into smaller clusters using the same algorithm. With the algorithm returning promising results, I put the data into JSON files that could be easily wired into a front end app.
FBI, UFOs, and OCR
In addition to working on video analysis for the Abbottabad archive, I had the opportunity to work on other projects and look into other ways of understanding large document sets. One such project involved performing optical character recognition (OCR) on old, often poorly scanned documents that are common in government archives. OCR is helpful because it extracts the text so that it can be displayed or used in text analysis. However, since the text is often mangled by the scanning process, the results from the OCR are often varied.

Initially, my job consisted of determining which programs and pathways result in the most accurate OCR from PDFs. As a test set, I used old FBI records about UFOs, which consist of scanned handwritten documents, typewritten pages, and newspaper clippings. After researching and testing different products and programs, including Google’s Tesseract, ABBYY FineReader, Adobe Acrobat and a handful of Python libraries, I found that the accuracy of the resulting text varied with each document. That said, I transitioned to creating a program that could determine the accuracy of an OCR output text file. This program helps determine which resulting text file has the fewest errors and can alter the text files to correct words with small misspellings in order to identify the best version of the text to use.
Wikipedia by Page Views
Another archive we’re interested in working with and understanding is Wikipedia. Wanting to find a way of prioritizing the pages, I looked at the page view statistics. The goal was to curate a list of every article in Wikipedia and its median monthly hit count from 2017, which could later be used to provide hierarchy in a visualization of the document set.
With over 15 million articles represented in the logs, the page view statistics for English Wikipedia proved challenging to parse and analyze. (There are about 5.5 million articles in all of English language Wikipedia, but there is significant churn—articles added and removed—over time.) In order to circumvent a data leak that resulted from trying to store too much information in one variable, I had to parse 1/12th of the data at a time. I also had to split the storage of the data between a dictionary, a list, and a set, because otherwise searching for pertinent articles ended up being far too inefficient.
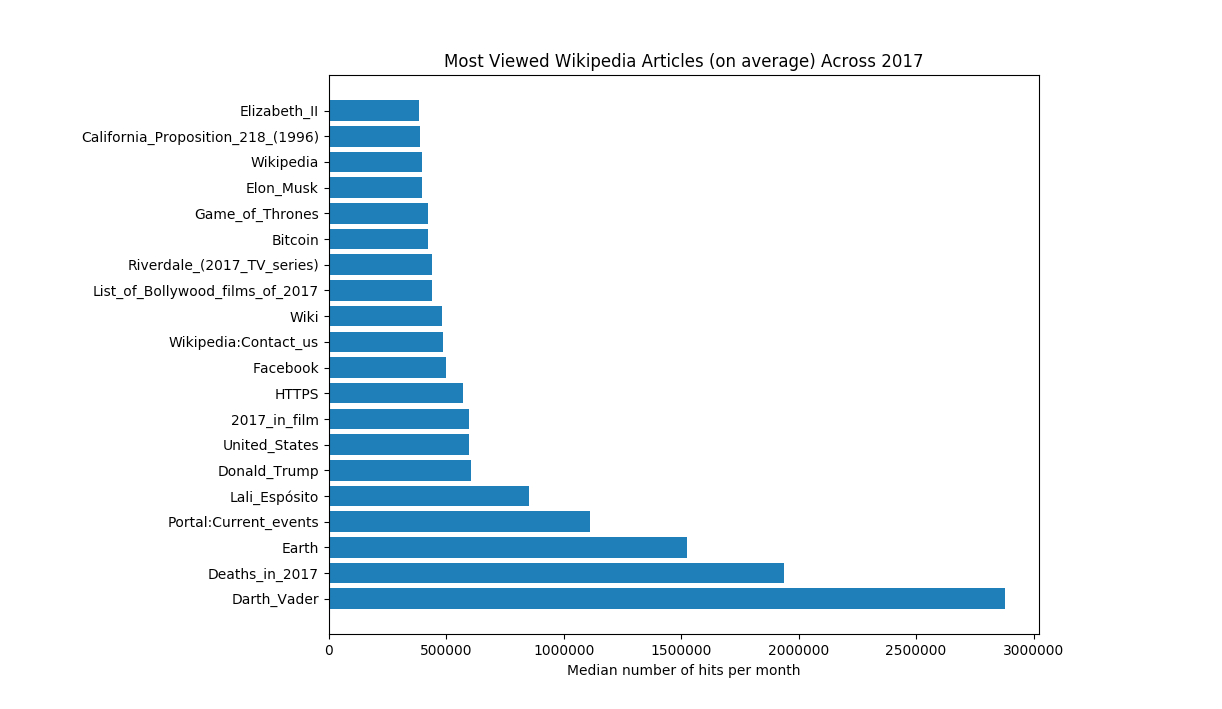
Working with a data set as vast and diverse as the Wikipedia database was incredibly interesting. By the end of the project, I discovered that the article with the highest median monthly hit count in 2017 was Darth Vader (perhaps due to the release of The Last Jedi), followed by articles such as Donald Trump, Game of Thrones and, on a more morbid note, Deaths in 2017.
Over the course of the summer, I delved into a lot of topics including facial recognition, machine learning, natural language processing, clustering algorithms, and efficiency optimization. I was also exposed to a simultaneously creative and technical mode of operation. My work not only taught me about computer science and programming, but opened my eyes to a new way of thinking about data and information.