We’ve been thinking about this a lot over the past few months in the context of exploring large corpora. Whether it’s years of email, transcripts of podcast episodes, or the Panama Papers, there should be intuitive tools to help you navigate and gather insight from the ever-larger document sets around us.
Even as the amount of data being collected has skyrocketed over the last two decades, improvements in storage, search, and analysis of large datasets have outpaced the progress in human-centered design and making information understandable to people on an everyday basis.
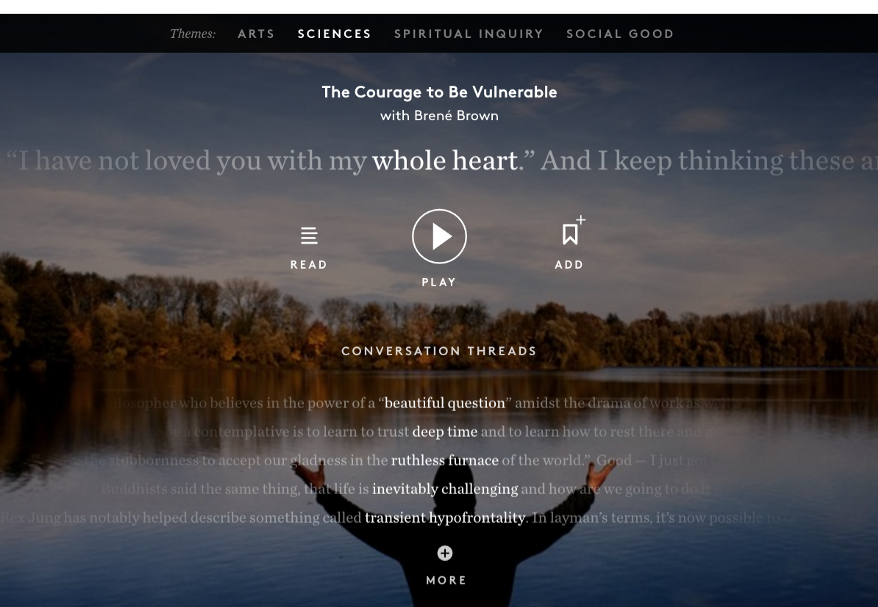
We’ve been grappling with these problems on several of our projects as we close out the year. We recently partnered with the On Being team to create an archive discovery tool. With more than a decade of material, this app is designed to help people find their way amongst hundreds of episodes, following threads of interest and finding new ones. The interface is based on “whispers” — short pieces of text to pique one’s curiosity — that feel a bit like overhearing part of a fascinating conversation between the host and her guests. Behind the scenes, we developed algorithms to find and highlight these unique parts of the conversations, as well as modeling the connections between the episodes.

In our other projects, we built an interface to help people understand the connections and interrelatedness of enormously complex legal documents, as well as pursuing research on understanding large document sets. While these use methods like clustering and topic modeling, the real focus is on how to make the information as relatable as possible to end users, and the experience itself as fluid, engaging, and beautiful as possible. We look forward to continuing this work in the new year.
We’d love to hear what you’re working on, what you’re curious about, and what messy data problems we can help you solve. Drop us a line at hello@fathom.info, or you can subscribe to our newsletter for updates.