
It’s early 2015, and a reporter name Bastian Obermeyer at a German newspaper called Süddeutsche Zeitung gets an email. Eight words.
“Hello. This is John Doe. Interested in data?”
And, well, you’ve probably heard about what happened next.


This is Especially Big Data. A podcast from Fathom information design where we examine the many things data can teach us and and the challenges ways we can get that data in the first place. I’m Charlie Smart.
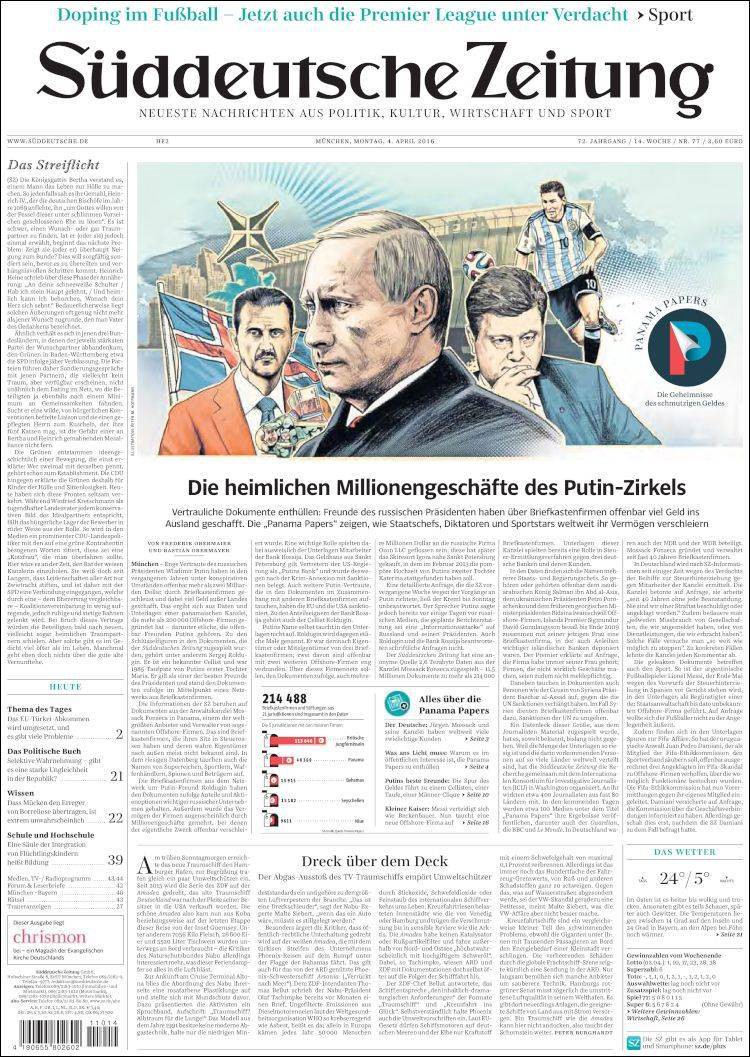
The Panama Papers. It was the biggest leak in journalism history, linking hundreds of politicians, athletes, celebrities, and other elites to ethically dubious offshore businesses.
We’re talking about 2.6 terabytes of data that amounted to 11.5 million files that came from a Panamanian law firm called Mossack Fonseca.
That’s Mar Cabra.
I’m the head of the data and research unit at the International Consortium of Investigative Journalists.

When Süddeutsche Zeitung got the data, they reached out to the ICIJ and the two organizations collaborated on the investigation.
So it all centered on this law firm, Mossack Fonseca. Since the 1970s they had been setting up what are called “shell corporations” for wealthy people around the world. That’s basically a company whose only purpose is to handle financial transactions–it doesn’t actually make or do anything.
Now that’s not illegal per se, but the panama papers investigation found that at least some of these companies were being used for things like fraud, tax evasion, and money laundering. That’s all very illegal.
You’ve probably heard this all before–there were hundreds of stories published about this last Spring. But there was a ton of work that went into this project in the months leading up to that. And it answers an interesting question. How can you find interesting information in eleven million documents–the needle in the haystack? So for now… let’s go back to the data.

2.6 terabytes. That’s… a lot of data. If you filled it up with mp3s, you could listen to music nonstop and not hear the same song twice for more than five years. Even by the standards of the ICIJ, who are used to getting huge document leaks, this was something else.
So if you look at the 2.6 terabytes of the Panama Papers and you look at the previous investigations we had done at the ICIJ, two years ago we were dealing with 260gb of information, so now we’re dealing with ten times more.
That’s Mar Cabra again.
So imagine you’re at work and your boss calls you over and says, “hey, here’s 11 and a half million documents. I need you to read through them and tell me what’s important.”
What would you do? Where would you start? Does it even seem possible?
You wouldn’t be the only one with those questions.
When I was first told about this I was not super excited because I was like “oh my god how are we going to deal with this?” It’s such a big challenge. That was my first reaction. After I had time to digest it I was excited.
So one strategy could be to put on a pot of coffee and just start reading. And reading. And reading. But even with a team of people going through the documents together, it would take months–probably even years to get through them all.
What else could you do?
If the documents were all on a computer, then maybe you could start by searching for a few terms and working from there. That might work–if the documents were all nice text files, like word documents or excel sheets. But… there was one problem.
We had to deal with PDFs, we had to deal with images, we had to deal with emails, databases. It was dozens of formats that needed to be processed.
This is often a challenge when you’re dealing with large sets of documents anywhere. You might run into similar problems in an archive or library, where you have lots of old books scanned into a computer. They’re not very useful as just pictures of the pages, because you can’t search for text in a picture.
That was the same problem the ICIJ had with the panama papers.
The previous investigations were all PDFs or Excel. The main challenge here with the Panama Papers was that we had dozens of formats that needed to be processed and we had three million images that needed to be OCRd. We needed to extract the text from images.
OCR — that stands for optical character recognition. It’s when a computer is able to convert a picture of words into actual text. But it’s a really slow process—it could have taken months to process the number of documents Cabra and her team had. So they needed to improvise.
We started creating an army of servers that worked in parallel, parallel processing the data. We had 30–40 servers that were temporary servers that would take in files. So basically we had the power multiplied by 35 or even more.
But even with their “army of servers” processing the documents, it still took a while to get all of the files in order. Cabra said her team held on to the data for about three months–just organizing it and trying to figure out what was even in there–before they let any other journalists look at it.
Computers are great for working with numbers, but it’s much harder to make a computer understand words. So there’s often a lot of work that has to be put in up front to get the data into a state that’s even usable.
They ran into other problems, too. A large portion of the data was this database of Mossack Fonseca’s clients. That’s obviously really important, but…
We didn’t get it in one file, we didn’t get it in like a database format. We got it in a deconstructed way. It’s kind of like modern cuisine right, we got in in many different files actually like 3 million files that each had information about one of the records.
A lot of the work had to go into extracting the information from those files and putting it back together into one database.
So after months of working with this data at the ICIJ, it was finally time to share it. Not to the public, but to other journalists.
See even once all the data was formatted nicely, it was still way too much work for any one person to go through it all. Even a team like the ICIJ and Süddeutsche Zeitung had too much on their hands.
So they called in more than 400 journalists from around the world, from organizations like the BBC, Fusion, the Guardian and France’s Le Monde.
It was a huge collaboration–one of the biggest of it’s kind. But it was still a challenge, because most of these journalists weren’t data experts. Few knew how to access information stored in a database or how to parse and tease information out of this massive set of documents. They needed some kind of tool.
We had previously been using a software that is called project blacklight that is meant for libraries. So for example Columbia University uses it in their library. We thought searching for books was similar to searching for documents, so we adapted it to our needs.

I think there’s a pretty good overlap between libraries who understand metadata and how users are discovering things and data-driven journalism.
That’s Chris Beer. He’s a software developer at Stanford University where he maintains Project Blacklight.
When Blacklight was first developed, it came out of a digital humanities project that was searching a variety of databases and my colleague Bess Adler had a simple question: “what happens when you put library material into a search like this?”
This brings us to the second challenge in working with documents as data. Once you have them cleaned up and ready to be used, what do you actually do with them? How do you find the information you’re looking for without reading every page?
Blacklight is essentially a search engine interface. It’s the part that a user interacts with, where they can type in search queries and get responses back. It sits on top of Apache Solr, which is a big open-source search engine. Think of it like Google, but instead of searching the web, it’s searching whatever documents you give it.
It doesn’t really care how you got your data into the search index, once you do that you can expose it through blacklight.
And because Project Blacklight is open source, users can tweak it however they need.
It gives you a set of basic assumptions out of the box and then implementers can modify it in a way that makes sense for their users and their content.
And that’s exactly what the Panama Papers team did.
Mar: So the document search platform would allow you to filter. As a user, say I want to search… then you could filter through types of documents so ‘I only want to see the emails.’ Then you can see the date.
So they gave this—essentially this document leak search engine—they handed it over to reporters around the world, and they started making lots and lots of searches.
Basically you would search a name and see if there was a hit and then the reporter would have to look at the documents and see if there was anything interesting. So a lot of the discovery was done that way.
It wasn’t particularly fancy.
Many of the names that we found were names that we randomly searched in a search engine.
In fact, they made it even easier. Reporters could upload a whole spreadsheet of names and get a report back of who may have been involved. And they found lots and lots of names.
The president of Argentina, the PM of Iceland, soccer player Lionell Messi, Simon Cowell, and hundreds more. All linked back to this one Panamanian law firm.
So now they had the data and they had the names, but there was still more work ahead. They needed to find stories. Connections within the data between people. Sure, you could just do lots of searches and work out all the connections by hand, but there are much better ways.
For this part, Cabra said being able to visualize the data was crucial.
Our brains are able to read but not to connect the dots and that was what Linkurious was good for.
They used a software called Linkurious that let them see all of the people in their database as a big network. You could follow business connections through the chain, sometimes leading back to someone important. Like, say, Russian president Vladimir Putin.
We were able to look at dots in the screen, for the reporters that were not tech savvy they would be able to look at dots on a screen, click on a dot, and it would expand the connections around those people. A lot of reporters told us it was crucial for them to find the connections between the people they were investigating, they even found more names connected to their countries than before.
There was one last thing the Panama Papers team needed. Of course when you have hundreds of people working on a project together, you need some way for them to collaborate. So, they came up with a custom solution for that, too.
Very early in the project we realized we needed a platform to communicatewith each other. Basically we had been using previously in other projects a software called Oxwall. And Oxwall was a social networking software meant for dating, so basically it would have a form for user when you create your user that says “what are you looking for, male or female?” So we actually adapted that platform to our needs and to get our investigative journalists to “date” in an investigative way, to share leads with one another.
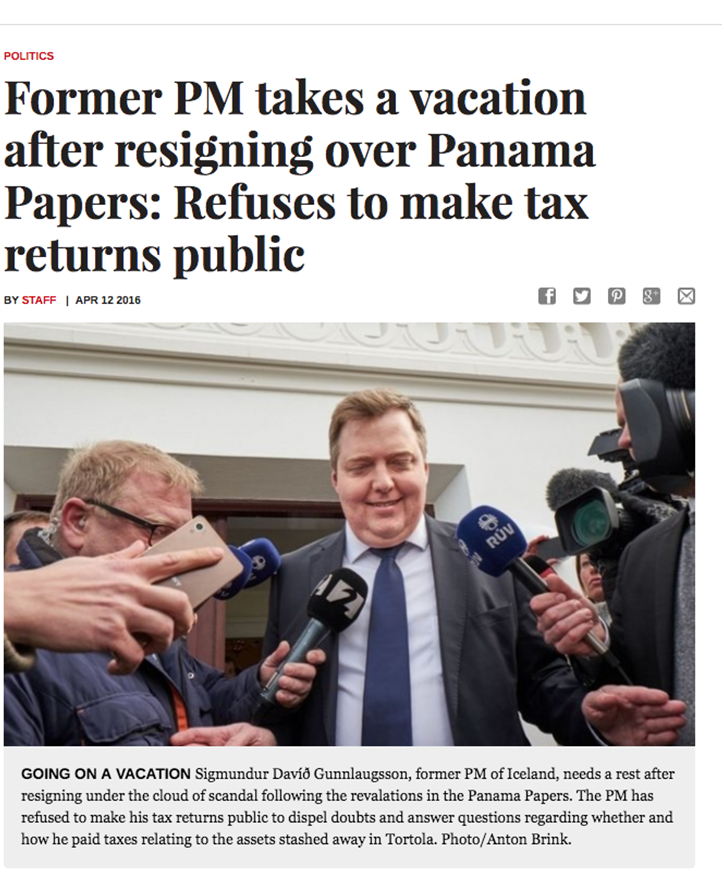
So after more than a year of working with these documents, all of the news organizations involved in the investigation published their stories on the same day. The impact was huge. It led thousands of audits and investigations, half a million dollars in fines for Mossack Fonseca, the law firm at the heart of it all, and forced the resignation of the Prime Minister of Iceland.
But what can we learn from the investigation itself? No doubt it was an incredible feat of journalism, but the tools and techniques used by the Panama Papers team can be applied to fields outside the realm of journalism too–librarians, data scientists, archivists, researchers, and people in lots of other fields can use many of these techniques.
Cabra said one lesson when you’re confronted with a massive pile of data is to slow down and take a step back.
One thing we learned in previous projects is look at it a lot before you start sharing it with others. So the first thing that we did was to do like a forensic analysis on what was in the hard drives that we got from Süddeutsche Zeitung. It was very important to us to look at what types of files were there because that would basically dictate the kinds of works that we do.
She said one thing she’d like to look into going forward is using machine learning to help guide people while they’re searching the documents.
My dream is — you know when you go to Amazon and it tells you ‘hey, you may be interested in buying this book or buying this product’ and they do that based on your previous searches and your previous purchases and they’re trying to adapt to you and what you’ve done previously with them. Well I want our future search engines and comments search platforms to do the same. ‘Hey, you found the prime minister of Iceland, maybe you’re interested in the president of Argentina.’
These are all important things to consider, because we produce more data today than ever in history. And a lot of that data isn’t in a simple format like a spreadsheet. Think about this. A report came out a few months ago which estimated that more than 200 billion emails are sent every day. Just a few decades ago it would have been hard to imagine data on that scale, but that’s just a fraction of the information that is passed around the web today. And since data — in any form — documents or numbers—isn’t going anywhere, we need to find ways to make sense of it.
For Chris Beer from Project Blacklight, that means working to make searching for data as easy as it can be.
Our goal as software developers in this ecosystem is to provide them the most relevant thing possible.
Oh and by the way, Beer didn’t know the Panama Papers team was using project Blacklight during the investigation, but he was thrilled when he found out.
It was a great surprise when it came out, I can’t remember the first time we saw it but it was certainly after the Panama Papers was published and someone emailed me asking “is this your Project Blacklight?” That was tremendously exciting.
For Cabra, data has become a regular part of her daily work as a journalist. She actually founded the first ever graduate program for investigative data journalism in her native Spain.
I think [data] is becoming more and more important in investigative stories because it allows us to expose issues happening in a systemic way, in ways you can’t show with just anecdotal evidence. I don’t foresee many investigations in the future that do not have an important data component.
So next time you’re at work and your boss hands you a stack of 11 million documents, take a breath before you storm out of the office. It’s tough work, but the Panama Papers investigation showed that it’s far from impossible.
Especially Big Data is a production of Fathom Information Design in Boston Massachusetts. This episode was produced by me, Charlie Smart with help from the rest of the crew at Fathom. Thanks to Mar Cabra and Chris Beer.
We’d love to hear what you’re working on, what you’re curious about, and what messy data problems we can help you solve. Drop us a line at hello@fathom.info, or you can subscribe to our newsletter for updates.