So far Mirador has been exploring health datasets beginning with NHANES, the National Health and Nutrition Examination Survey. Every other year, they travel the United States with a fleet of mobile examination rooms to survey 10,000 participants on hundreds of questions and factors. The result is an enormous, but well-developed database used by medical researchers in a number of fields. As a result many research papers are based on NHANES data. Using Mirador within a couple minutes you can take one of these research papers, adjust the variable parameters, and see the correlation that the paper is discussing.
Some of the powerful features of Mirador are the algorithms running behind the scenes and the speed at which parameters can be adjusted, sorted, and browsed simultaneously.
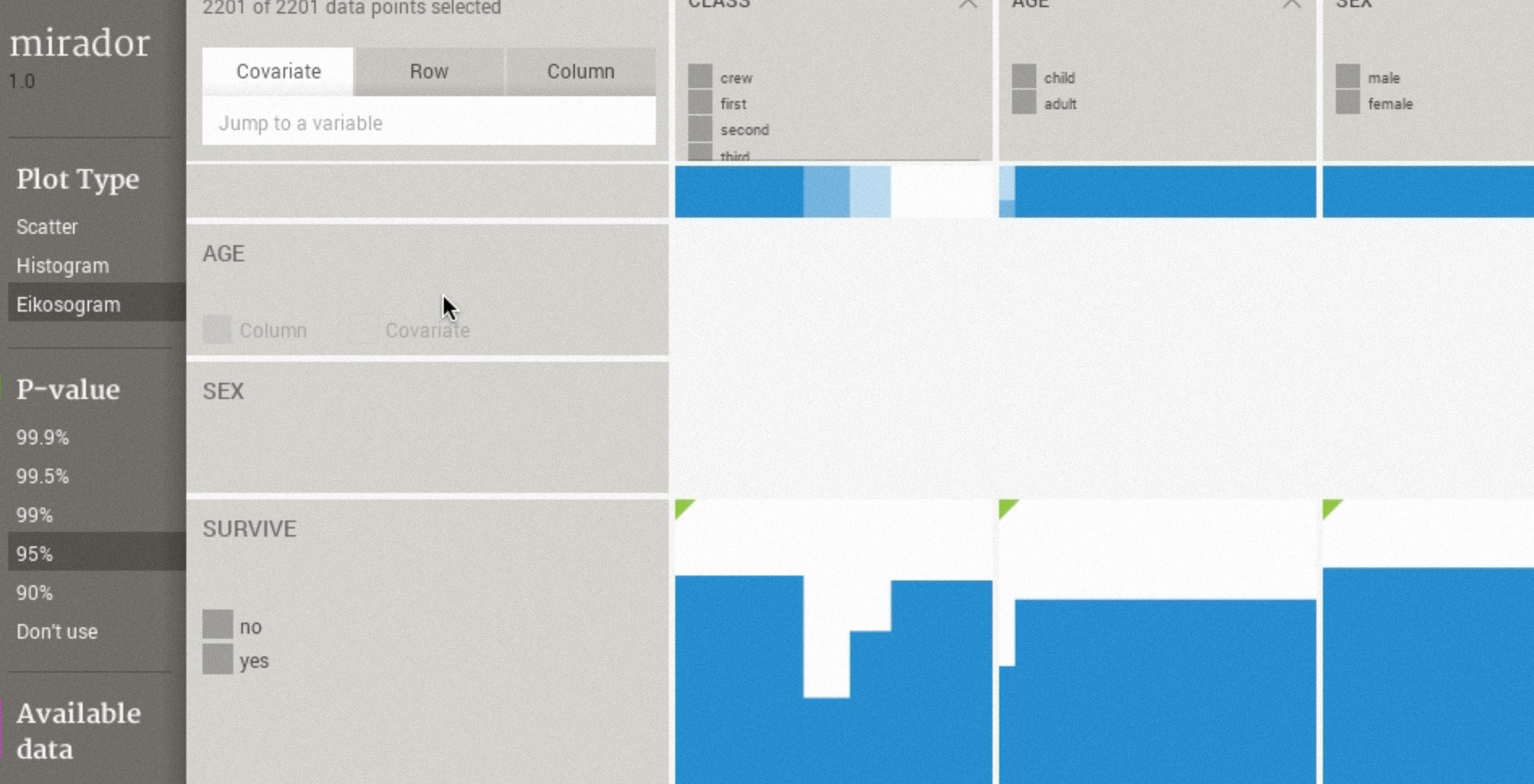
As a simple example, let's look at the Titanic. By adjusting outcome (i.e. "Survival") we see how the correlation between gender and class of the passengers changes.
The best way to get started is to read the manual and open one of the examples after downloading the app from the homepage.
We’d love to hear what you’re working on, what you’re curious about, and what messy data problems we can help you solve. Drop us a line at hello@fathom.info, or you can subscribe to our newsletter for updates.